[GNU Manual] [POSIX requirement] [Linux man] [FreeBSD man]
Summary
split - split a file into pieces
Lines of code: 1668
Principal syscall: write()
Support syscalls: open(), close(), stat(), execl(), fork()
Options: 26 (10 short, 16 long)
Descended from split introduced in Version 3 UNIX (1973)
Added to Textutils in November 1992 [First version]
Number of revisions: 214
The split utility is the older sibling of csplit with fewer ways to split input
bytes_chunk_extract()- The split procedure on byte chunks of input (-b n, k/n)bytes_split()- The split procedure on bytes of input (-b l/)closeout()- Closes the current output filecreate()- Creates a new output filecwrite()- Write to the output file, possibly creating a new oneignorable()- Tests if an error can be safely ignored (EPIPE when using filters)input_file_size()- Tests input read size and buffers dataline_bytes_split()- The split procedure on byte-limited lines (-C)lines_chunk_split()- The split procedure on chunks of input (-0..9, -l)lines_rr()- The split procedure on round-robin lines of input (-b r/)lines_split()- The split procedure on lines of input (-b)next_file_name()- Gets the next output file name, permuting suffixofile_open()- Opens a list of files, rotating descriptors as neededparse_chunk()- Parses the chunk options passed through -nset_suffix_length()- Constructs the suffix after parsing user input
die()- Exit with mandatory non-zero error and message to stderrerror()- Outputs error message to standard error with possible process termination
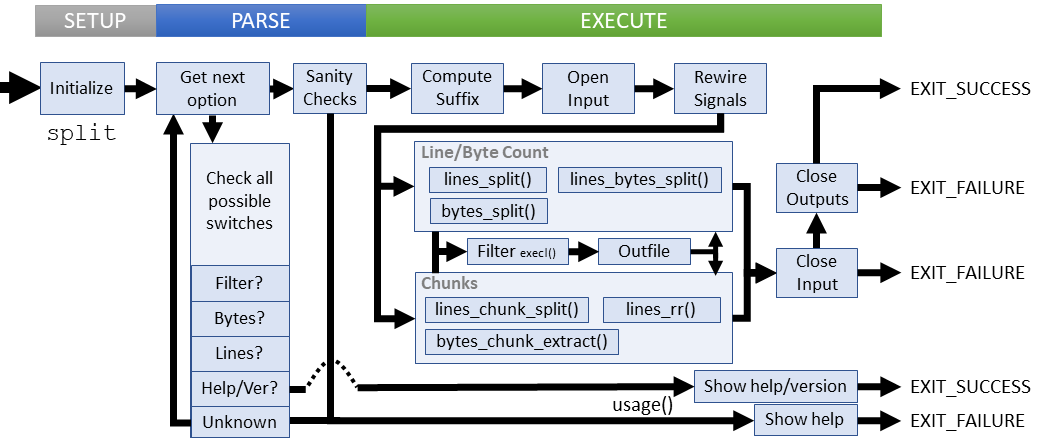
Setup
The split utility has several modes of operation, which determine the specified split procedure executed. The utility defines types for each mode:
type_bytes- Limits output files to a number of bytes of input (-b)type_byteslines- Limits output file to a number of bytes of complete lines of input (-C)type_chunk_bytes- Generates output file count limited to byte chunks(-n n, k/n)type_chunk_lines- Generates a number of files disregarding line separation(-n l/)type_digits- Ultimately becomestype_linestype_lines- Limits output to a number of lines of input (-l)type_rr- Generates a number of files using round-robin ordering (-n r/)type_undef- No user options discovered, defaults totype_lines
split uses several global flags and variables, including:
additional_suffix- The suffix to add beyond the default suffix (--additional-suffix)elide_empty_files- Flag to avoid creating empty files (-e)eolchar- The end of line character (-t)filter_command- The command to pipe output to (--filter)filter_pid- The PID of the filtering processin_stat_buf- The stat structure of the input fileinfile- The name of the input filen_open_pipes- The actual number of open pipes (index toopen_pipes)newblocked- The new set of blocked signalsoldblocked- The original set of blocked signalsopen_pipes- The list of open pipes (child processes)open_pipes_alloc- The number of possible pipe allocationsoutbase- The base name of output files (no suffix)outfile- The name of the output fileoutfile_mid- The end of the base name in the output file nameoutput_desc- The output file descriptorsuffix_alphabet- The index of characters for the suffixsuffix_auto- Flag to generate a new suffix, if neededsuffix_length- The length of the output file's suffixunbuffered- Flag to immediately move input to output (-u)verbose- Flag to enable extra feedback (--verbose)
main() adds a few more locals before starting parsing:
prefix_len- The length of the output file name prefixoptc- the next option character to processmax_digit_string_len- The maximum possible size of a file name (includes suffix and name)
Parsing
Parsing breaks down the user-provided options to answer these questions about handling input data:
- How should the input be split across output files?
- How should we mangle names to separate files (suffix, etc)?
- Should we use a special separator?
- Should output be buffered?
- Should we provide extra feedback to the user?
Parsing failures
These failure cases are explicitly checked:
- User doesn't provide a useful line/byte value
- Nonsensical block size provided (undocumented feature)
- User specifies multiple or empty separating characters
- Invalid suffix length provided
- User provides unusable chunk sizes with the -n option
- Unknown option used
User specified parsing failures result in a short error message followed by the usage instructions. Access related parsing errors die with an error message.
Execution
Although split has a myriad of split modes and options, they all fall in to two strategies: 1) Control the input read size and generate as many output files as needed; or 2) Control the number of output files and read chunks divided among the files. Also, when the output is to be sent to another command for filtering, then both signal handlers and I/O streams need to change to consider the command to run prior to output.
Execution involves six distinct procedures, each of which deserves its own discussion. I'm going to save that for the line-by-line walkthrough and discuss only common operations. Here's the general idea:
- Set the suffix length for the output files using the user-provided options
- Open the input file as binary read-only
stat()the input file for size estimated- Test reading from the file for chunk reading cases
- Reset the signal handlers if we're using a filter to handle incident SIGPIPEs
- Invoke the desired procedure based on user requirements:
lines_split()bytes_split()line_bytes_split()lines_chunk_split()bytes_chunk_extract()lines_rr()- Each procedure is unique, but generally do the following:
- Opens an output file, possibly redirecting to another filter process via fork()/execl()
- Writes from input to output pipe
- Checks when a new file is required and opens with the same properties and a new suffix
- Close the input
- Close all output files
Failure cases:
- Any errors reading or writing to file descriptors/streams
- Unable to open or close I/O files
- Unable to read from input source
- Unable to set environment for filter
- Unable to invoke filter command
- Failure in filter child process
- Unable to create/truncate a new file
- Unable to generate a new suffix
All failures at this stage output an error message to STDERR and return without displaying usage help