[GNU Manual] [POSIX requirement] [Linux man] [FreeBSD man]
Summary
od - write files in octal or other formats
Lines of code: 1983
Principal syscall: write()
Support syscalls: open(), close()
Options: 38 (27 short, 11 long, does not include legacy digits for field skip)
Descended from rm introduced in Version 1 UNIX (1971)
Added to Textutils in November 1992 [First version]
Number of revisions: 254
check_and_close()- Tests a stream for errors and closes itdecode_format_string()- Decodes the modern format stringdecode_one_format()- Creates the spec format by reading the -t option argumentdump()- Top level od procedure: read, format, writedump_hexl_mode_trailer()- Procedure for single character view ('z' trailer)dump_strings()- The level procedure for od -Sformat_address_label()- Formats pseudo-address label in legacy modeformat_address_none()- Applies no address formatformat_address_paren()- Applies parenthese to a pseudo-address (label)format_address_std()- Applies the standard address formats for all basesget_lcm()- Gets the least common multiple of spec sizesopen_next_file()- Opens the subsequent file from the processing listparse_old_offset()- Parses legacy offset inputprint_(TYPE)- A family of ten functions to print a block of standard C typesprint_ascii()- Outputs a block of escaped ASCII textprint_named_ascii()- Prints in named-character mode (7-bit)read_block()- Reads a block of bytes into a given bufferread_char()- Reads a single byte into a given positionsimple_strtoul()- Converts a string to a long valueskip()- Skips headers by repositioning read pointerwrite_block()- Writes the now-formatted block to STDOUT
die()- Exit with mandatory non-zero error and message to stderrerror()- Outputs error message to standard error with possible process termination
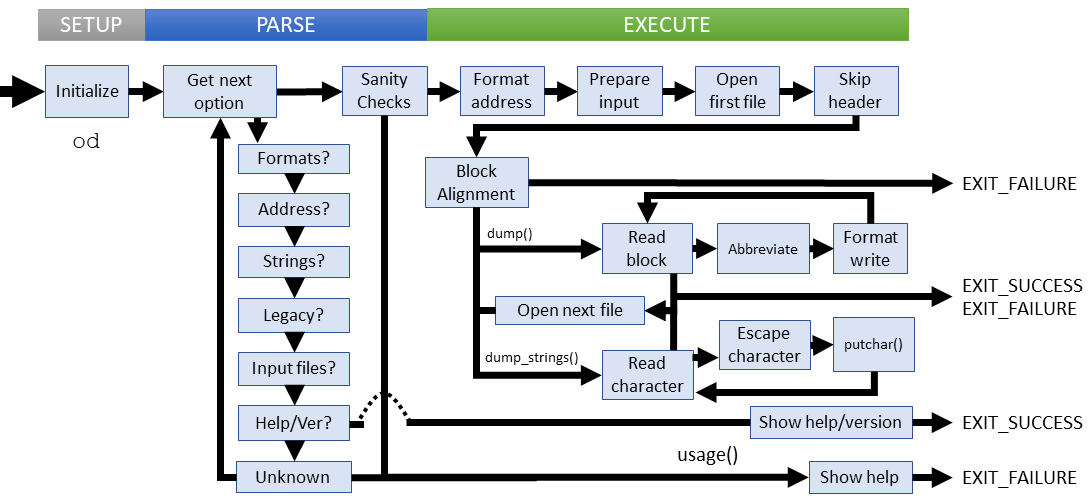
Setup
The od utility defines an important structure, struct tspec, built from user input and applied to data before output. Reach format contains one of the printing functions as well as size and padding information.
od uses many global variables and flags to support the conversion operations, including:
abbreviate_duplicated_blocks- Flag to convert duplicate blocks to asterisksaddress_base- The number base address are displayed in (-A)bytes_per_block- The number of input bytes formatted per output linebytes_to_hex_digits[]- Array to map hex widths, indexed by byte widthbytes_to_oct_digits[]- Array to map octal widths, indexed by byte widthbytes_to_signed_dec_digits[]- Array to map signed decimal widths, indexed by byte widthbytes_to_unsigned_dec_digits[]- Array to map unsigned decimal widths, indexed by byte widthcharname[][]- The names of non-printable characters indexed by value*default_file_list[]- The file list used if none are provided (STDIN)end_offset- The first byte after the last byte formatted**file_list- The list of input files on the command lineflag_dump_strings- Flag to dump strings with -Sflag_pseudo_start- Flag if a legacy pseudo-address was usedhave_read_stdin- Flag set if input was read from sTDIN*in_stream- The input file stream after opening*input_filename- A reference to the command line file namesinput_swap- Flag to use native endianesslimit_bytes_to_format- Flag set if only certain ytes are formatted (-N)max_bytes_to_format- Limit the input reading to this many bytes (-N)n_bytes_to_skip- Number of input bytes to skip (-j)n_specs- The number of specifications definedn_specs_allocated- The number of specifications allocated (possibly some unused)string_min- The minimum length of strings requested (-S)traditional- Flag to support legacy arguments*spec- Global array of format specifications
main() introduces a few local variables:
desired_width- The width requested by the user (-w)i- Generic iterator used in several placesl_c_m- Holds the least common multiple of format specsmodern- Flag set if we're using modern od syntaxmultipliers[]- Array of magnitude suffixesn_files- The number of input files specified on the command lineok- The final return statuswidth_per_block- Holds the minimum block width across all format specswidth_specified- Flag set if the user requested a specific width (-w)
Parsing
Parsing answers the following questions to define the execution parameters
- How should the addresses be displayed?
- Should we skip some bytes (header)?
- What formatting should be applied to the data?
Construction of tspec format structures occurs during parsing as they are encountered
Parsing failures
These failure cases are explicitly checked:
- Trying to process many files in legacy mode
- Choosing an unknown address format
- Suggesting string lengths larger than SIZE_MAX
- Applying format types to string dumps
- Unknown option used
User specified parsing failures result in a short error message followed by the usage instructions. Access related parsing errors die with an error message.
Execution
od operates as you would expect: Read input, apply format, write to output. A closer look at the procedure shows:
- Compute address format
- Gather input file list
- Open first input file and skip header
- Compute block length and padding for block alignment
- Execution branches to either
dump()ordump_strings()based on the user option -S - Regular dump:
- Read the next block -- EOF opens the next file and retries read
- Tests block for previous match and handle abbreviations
- Print the address
- Call the tspec format for the associated block
- Repeat sequence until the last block of the last file is read
- String dump:
- Read the next character -- EOF opens the next file and retries read
- Process possible escape strings
- Write the processes character
- Repeat sequence until all characters of all files processed
Failure cases:
- Reading or writing failures
- Skip increment too large
- Invalid string character encountered
- Unable to close input files or standard input
All failures at this stage output an error message to STDERR and return without displaying usage help